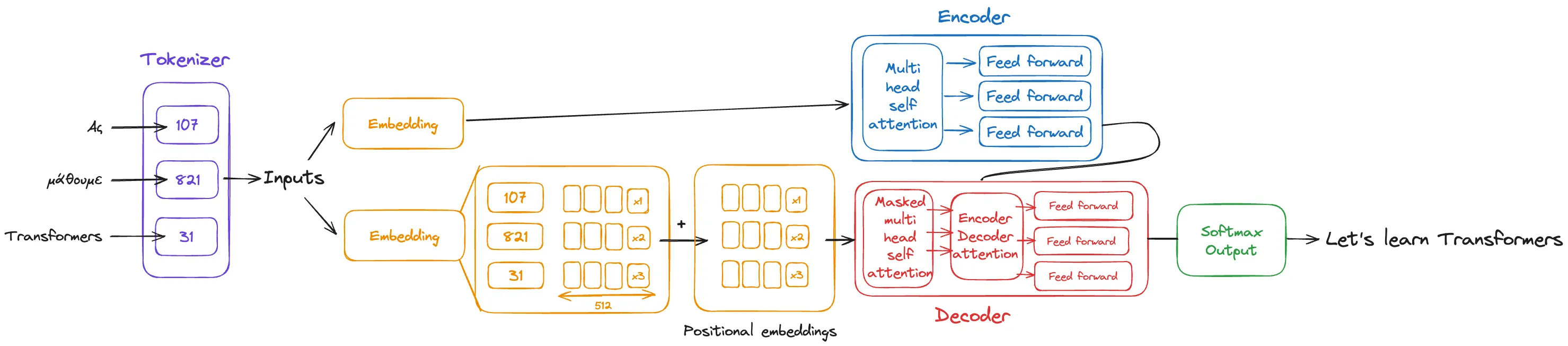

The Transformer Architecture From a Top View
The project is available online on Towards AI.
The state-of-the-art Natural Language Processing (NLP) models used to be Recurrent Neural Networks (RNN) among others.
And then came Transformers.
Transformer architecture significantly improved natural language task performance compared to earlier RNNs.
Developed by Vaswani et al. in their 2017 paper “Attention is All You Need,” Transformers revolutionized NLP by leveraging self-attention mechanisms, allowing the model to learn the relevance and context of all words in a sentence.
Unlike RNNs that process data sequentially, Transformers analyze all parts of the sentence simultaneously. This parallel processing capability allows Transformers to learn the context and relevance of each word about every other word in a sentence or document, overcoming limitations related to long-term dependency and computational efficiency found in RNNs.
But let’s explore the architecture step by step.
Continue your read on Towards AI.


Leave a Comment