

Emotion Detection on Movie Reviews
The objective of this project is the Emotion Analysis of sentences that are comming from movie reviews, using Machine Learning. An attempt will be made to construct a classifier capable of classyfying a sentence in one of the 6 basic categories of emotion which are anger, disgust, fear, happiness, sadness, surprise, and the category of non-emotion.
Things I did include:
- Created a new dataset using inter-annotator agreement
- Applied feature selection with tf-idf and chi-square methods
- Performed 15 text pre-processing techniques and their combinations
- Created and tested 14 new features in feature engineering
- Applied ensemble learning
- Used the resulting classifier in 6 movies
1. Creating the Dataset
The IMDbPY was used, a free Python package for the retrieval and manipulation of data from the largest movie database IMDb. Movies with more than 40 reviews were randomly retrieved and their reviews were stored in a file. Subsequently, representative keywords were chosen for each emotion category. These words can be seen in the following table.
| Emotion | Keywords |
|---|---|
| Anger | angry, annoyed, gloomy, depressed, unhappy, down, disheartened, sorrowful, painful, guilty |
| Disgust | stupid, sucks, irritated, humiliated, disgusted, nauseatng, sickening, contempt, repelling, unpleasant |
| Fear | afraid, frightened, fearful, horrified, nervous, paniched, alarmed, phobia, scared, insecure |
| Happiness | awesome, happy, amused, fantastic, excited, pleased, cheerful, love, great, amazing |
| Sadness | sad, lonely, gloomy, depressed, unhappy, down, disheartened, sorrowful, painful, guilty |
| Surprise | astonished, bewildered, survrised, confused, sudden, unaware, shocked, perplexed, what, unexpected |
Reviews were extracted that contained the above words, resulting in a total of 2,514 sentences. We need labels for supervised machine learning, so 3 human judges were selected to classify each sentence into one category. The question that they had to answer was “Classify the sentence according on the sentiment it exudes”. The choice of the no-emotion and mixed-emotion were also possible. The judges were first trained on already classified examples in order to be more confident.
It is very normal that the human judges will disagree on several sentences. There exist metrics which quantify the agreement between the judges called inter-annotator agreement. I used Cohen’s kappa which is used to compare the degree of consensus among reviewers in categorizing sentences into mutually exclusive categories. Results between each judge pair are shown below.
| Emotion | 1–2 | 1–3 | 2–3 | Average |
|---|---|---|---|---|
| Anger | 0.43 | 0.50 | 0.44 | 0.46 |
| Disgust | 0.55 | 0.51 | 0.49 | 0.52 |
| Fear | 0.61 | 0.72 | 0.66 | 0.66 |
| Happiness | 0.72 | 0.78 | 0.71 | 0.74 |
| Mixed Emotion | 0.39 | 0.47 | 0.41 | 0.42 |
| No Emotion | 0.63 | 0.69 | 0.64 | 0.65 |
| Sadness | 0.45 | 0.53 | 0.40 | 0.46 |
| Surprise | 0.31 | 0.53 | 0.35 | 0.40 |
| Total | 0.51 | 0.59 | 0.51 | 0.54 |
Values differ between emotions and between judges. The biggest are for happiness and fear. This means that the reviewers on IMDb express these emotions with more clear tone using words that define them easier. On the other had, the lowest values are for surprise and mixed emotion, and this is an expected behavior as the first is often confused with others and the latter has been added to categorize sentences that do not belong to any of the other categories. Nonetheless even a Cohen’s kappa value of 0.40 is considered a good agreement.
To finalize the dataset, I kept only sentences where at least 2 judges agreed on the category and added that label to the sentence. In total 2,002 sentences are contained in the final dataset.
2. Feature Selection
The total features (tokens) before feature selection are 5,636. I used tf-idf and chi-square methods to rank the features and applied different cutoffs for the top ones. These 2 methods and the different cutoffs were compaired among 8 classifiers namely Decision Tree, KNN, Bernoulli Naive Bayes, Ridge, Logistic Regression, Passive Aggressive, SGD and Linear SVC.
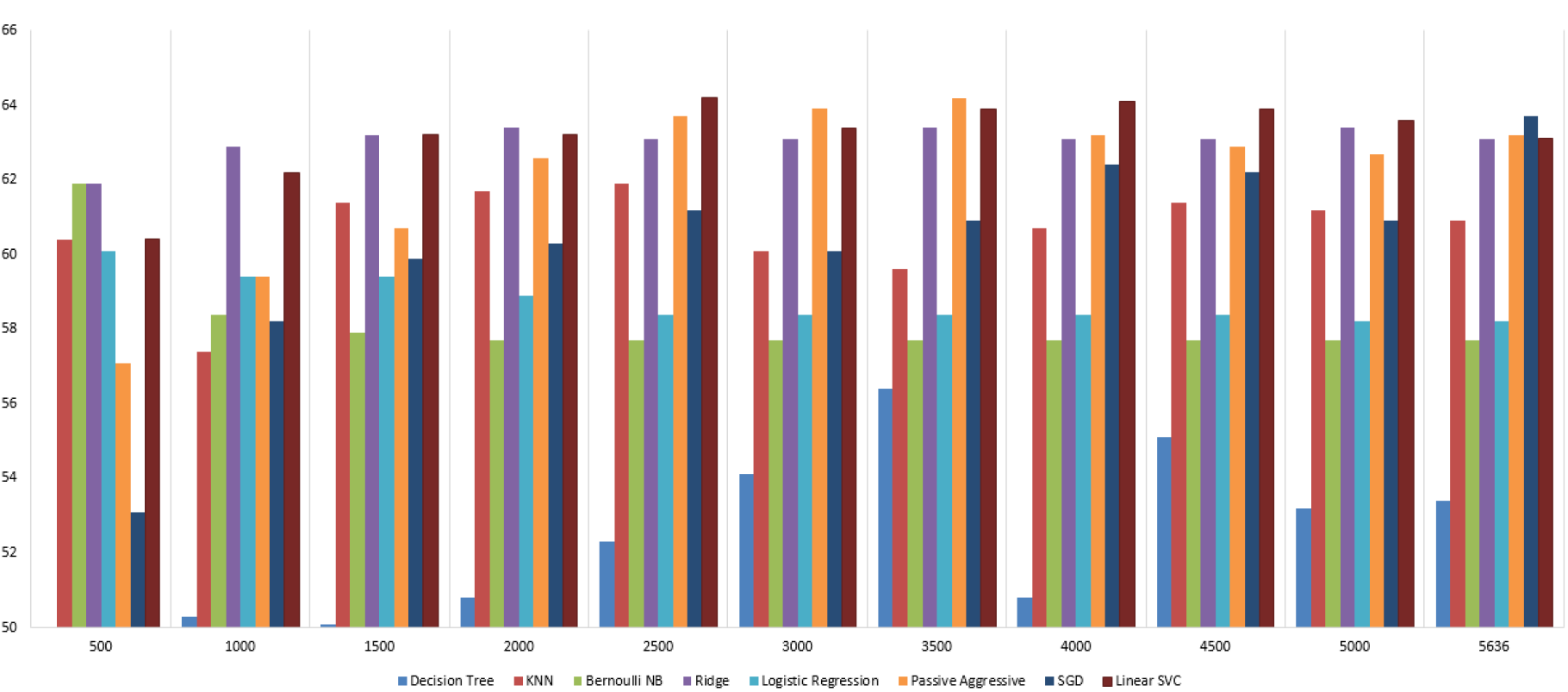
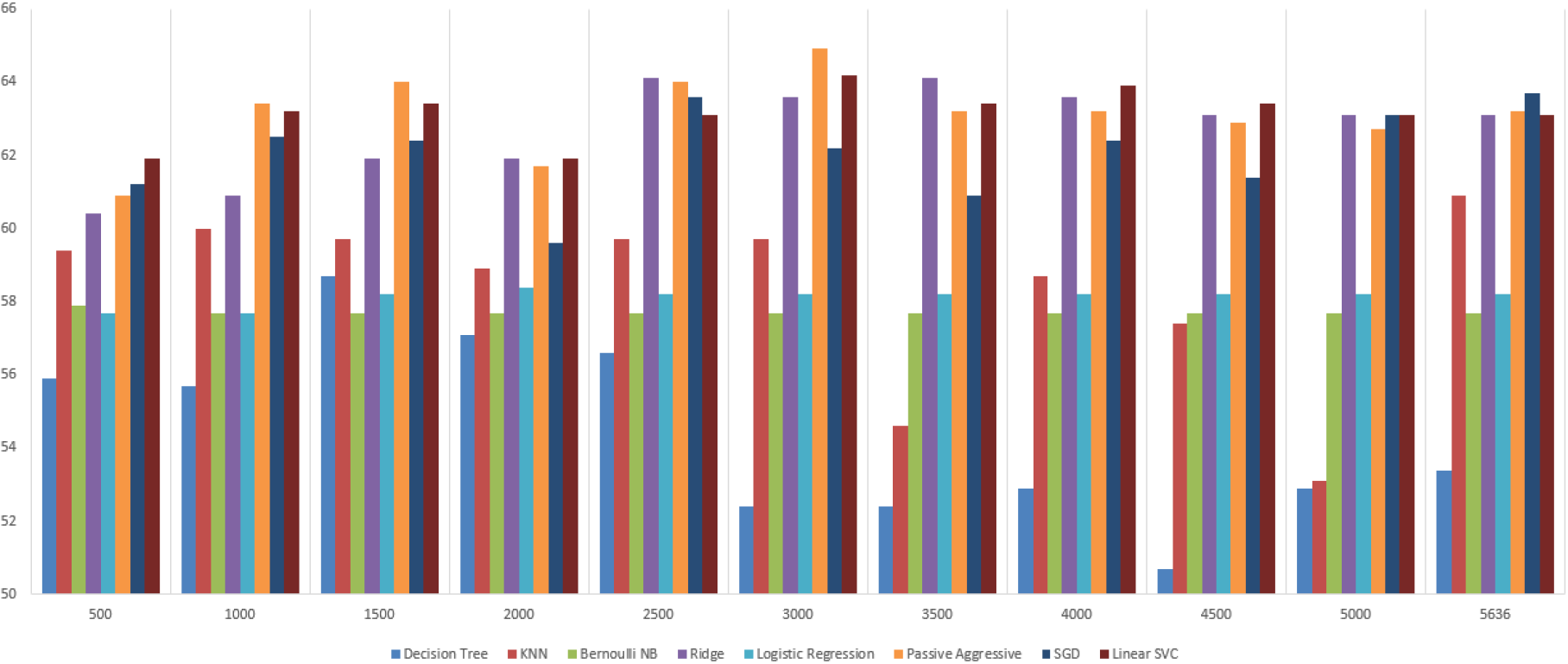
Based on the above plots I chose chi-square. It uses less features for the same accuracy, meaning that it reduces the dimensonality and thus the computational complexity and the danger of overfitting. The feature cut-off that I chose is 3,000 features in a bag-of-word representation.
2. Text Pre-processing
Next step is the text pre-processing. I used 16 techniques and their combinations. I provide code on my github for these python pre-processing techniques, which has gathered over 120 stars. This code is also the starting point for two scientific publications entitled A Comparison of Pre-processing Techniques for Twitter Sentiment Analysis and A Comparative Evaluation of Pre-processing Techniques and their Interactions for Twitter Sentiment Analysis.
While combinations of these techniques provided better results in the aforementioned papers, they did not for this dataset. Using only one techniques called Replace Repetitions of Punctuation I got the best results. The most used word of the dataset are:
3. Feature Engineering
I feature engineered 14 new features which are basically counts of particular linguistic characteristic in the sentences. Some of them include countExclamationMarks, countAllCaps, countEmoticonHappy, countElongated, countNegations, countEmoticonSurprise and countEmoticonAnger. The last three improved the model.
On top of that, 3 emotion lexicons were tested, namely NRC Emotion, Emo Sentic Net and Depeche Mood. Given that my dataset is consisted of movie reviews and these datasets are not specialized in a topic like movies, lets see their coverage on the dataset. By coverage I mean how many words of the dataset are present in each lexicon. The NRC Emotion contains 33.7% of the dataset’s total words, the Sentic Net only 19.7% and the Depeche Mood 49.6%. As there is no good coverage, these lexicons prove not helpfull in the classification accuracy. I confirmed that by training the model considering these lexicons, and indeed, performance dropped.
4. Ensemble Learning
I used majority voting ensemble classification to improve my results. Before that, I tuned all the algorithms to their parameter values. Majority voting is very simple. It classifiies a sentence with 3 algorithms and keeps the predicted label of the majority. The 5 best algorithms were tested. Linear SVC, Bernoulli Naive Bayes, Ridge, Passive Aggressive and Linear SVC. The best combination was with Bernoulli Naive Bayes, Passive Aggressive and Linear SVC.
The final accuracy of the model, considering all the improvements (feature selection, text pre-processing, feature engineering, tuning, enxemble) is 65.9%. As accuracy is not a good metric on unbalanced data, the F-measure was also computed. F-measure is the harmonic mean of precision and recall. It is equal to 62.1%. This is a high F-measure score for a classification problem with 7 possible labels.
5. Using the model in unknown data
I chose 6 movies with different ratings and genres. I will compare the ratings from popular movie websites (metacritic, IMDb, rotten tomatoes, theMovieDb) with my emotion classification. For each of the 6 movies, I extracted 100 reviews, resulting in about 1500 sentences.
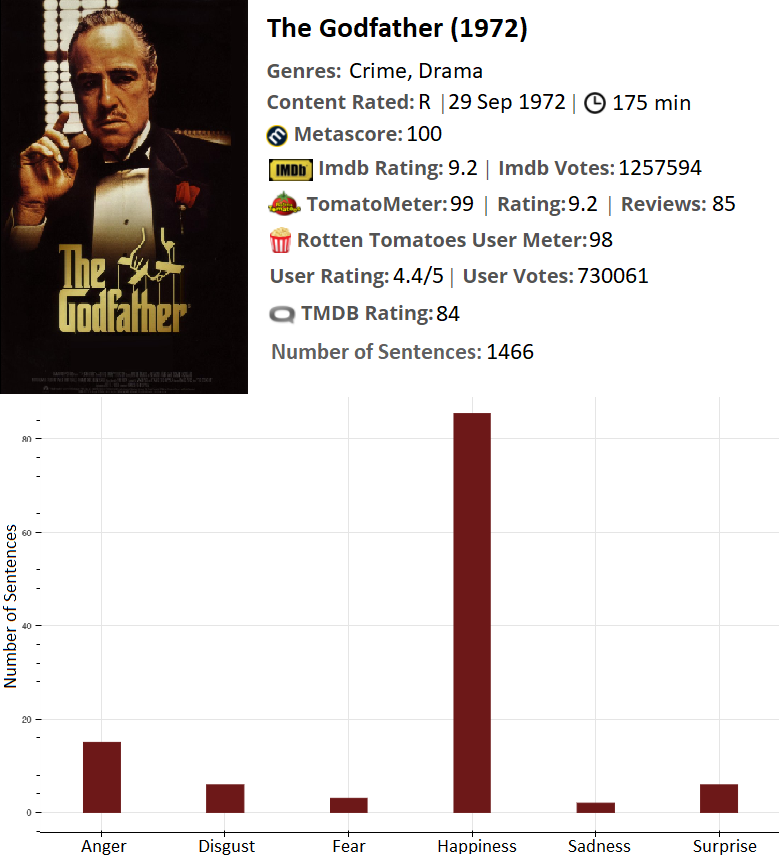
The first movie to test is The Godfather. One of the best movies of all time. My model agrees with the various movie websites as the emotion happiness is dominant. There is also a small number of anger sentences like “It’s a decent starting premise, but annoyingly, every time an avenue of interest opens up, the film either bypasses it or shuts it down completely” and “Jealousy, betrayal, anger and revenge are all key themes here, and the film is inevitably punctuated by moments of graphic and shocking violence”.
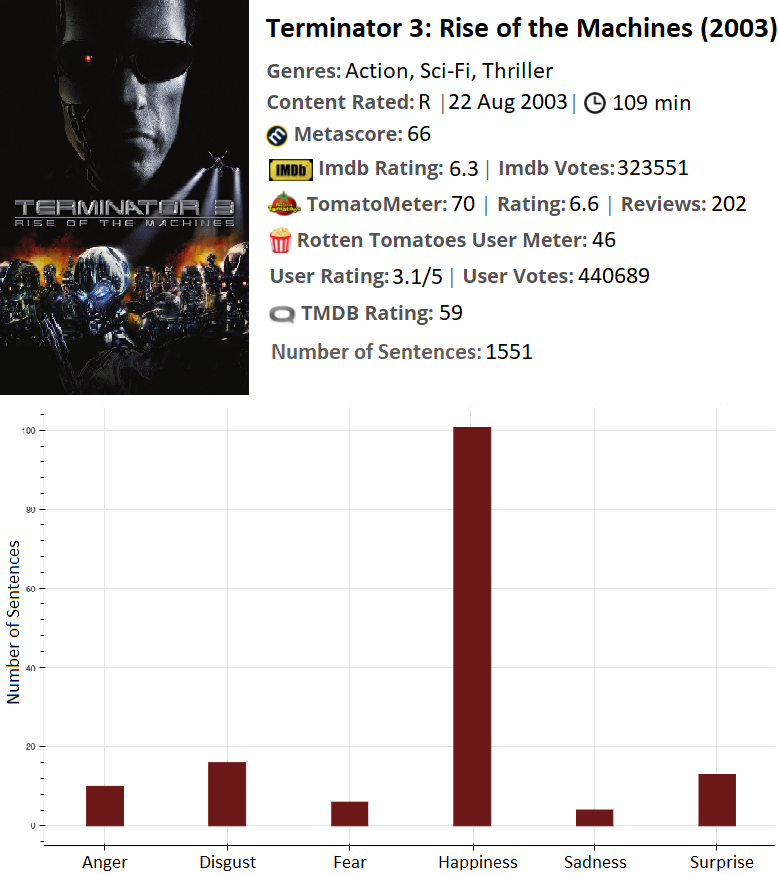
The third Terminator movie did not found the love in user rating like the previous two. My model suggests that this is a false conclusion, because there is a lot of happiness in the reviews. For the record, this movie has a great number of surprise sentences, given the fact of the rarity of this emotion. An example of surprise sentence is “I’m really surprised at all the negative reviews T3 is receiving”.
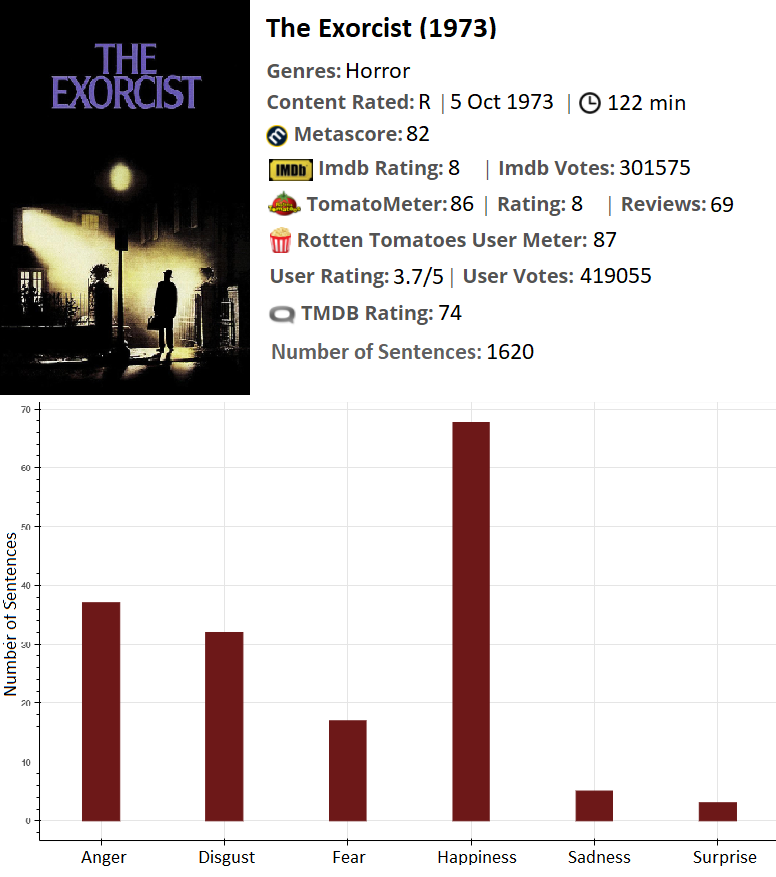
The Exorcist is a classic horror movie with high rating for a horror movie.
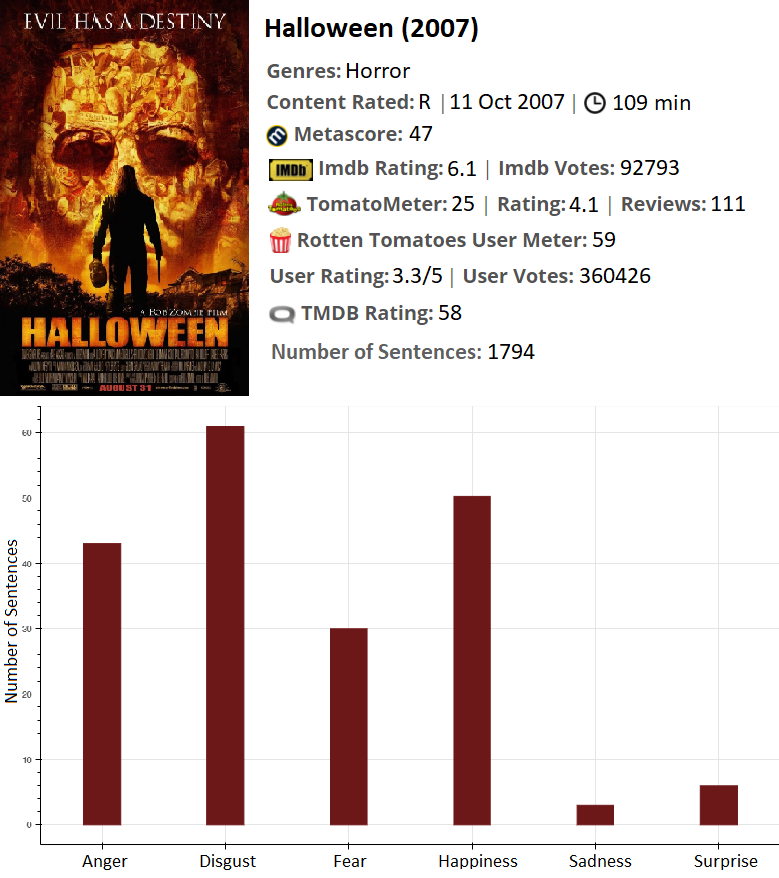
Halloween is another horror movie. My model suggests that this movie is more terrifing than the Exorcist.
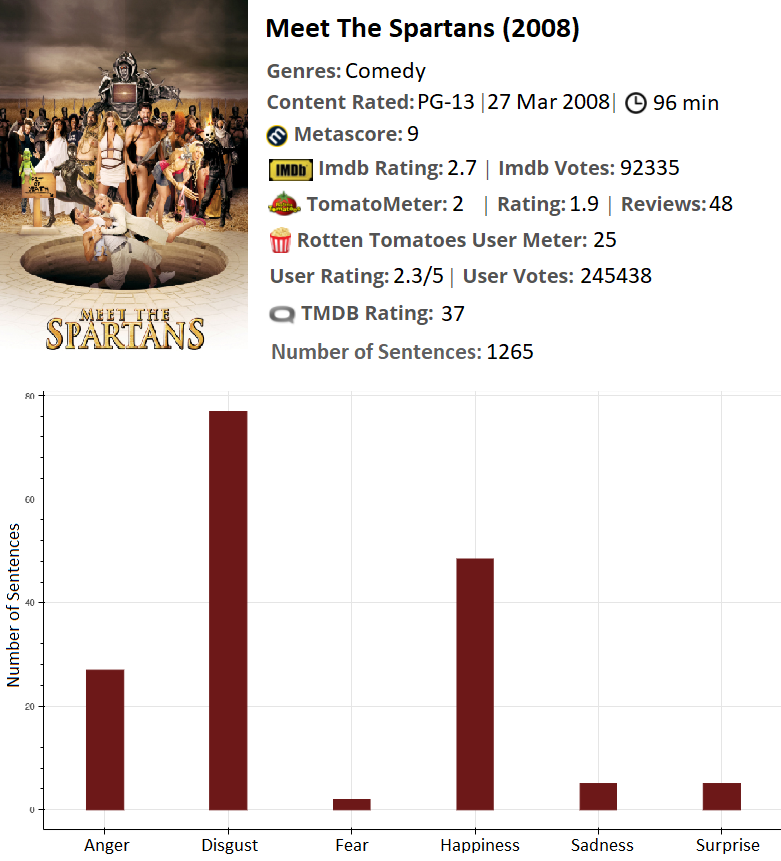
It is considered as one of the worst movies of all time. But this does not mean that viewers didn’t enjoy and had fun with it. There are a lot of happiness reviews as this movie is a comedy.
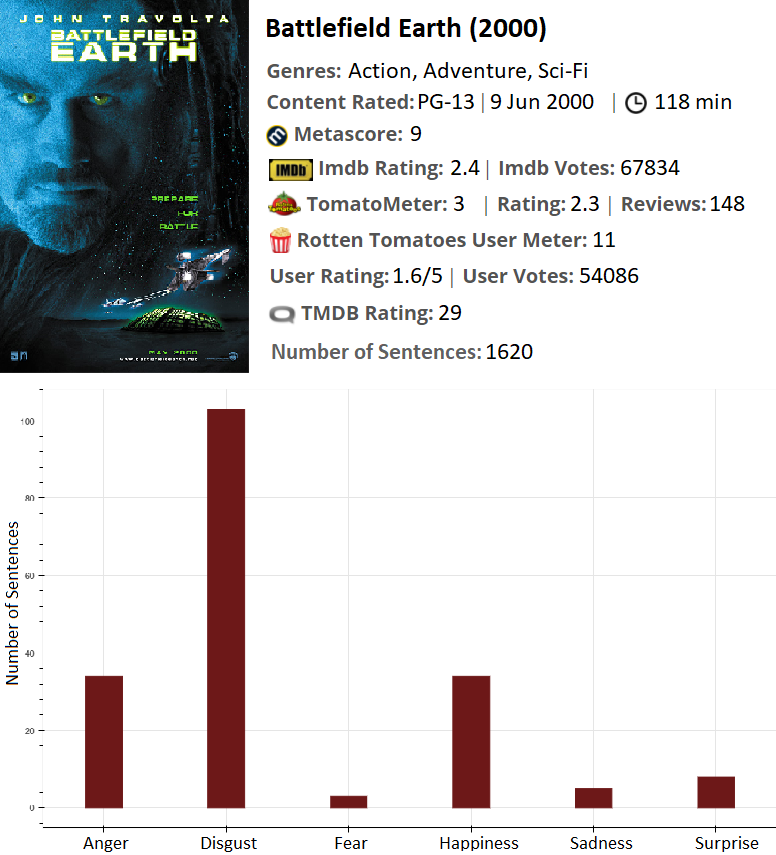
Battlefield Earth is also another movie which is characterized as one of the worst. It has a lot more disgust and a lot less happiness than the previous movie.
We can conclude that mere rating is not enough for a movie, and we can include more color to it classifying emotions.


Leave a Comment